The template mechanism in C++ allows classes and functions to be templated on arbitrary types and integer values. It does not allow templating on floating point values. There are many good reasons for this, and they generally relate to the lack of guarantees about floating point arithmetic. As a result, subtle differences (for instance in the compiler version, the CPU settings, etc) could result in different classes being instantiated and different code being compiled. Even worse, CPUs such as the x86 have one part internally which works in 80 bit precision (the x87 unit), and another part which works internally in 64bit precision (the SSE2 unit). If the compiler were to use both units (gcc can compile code to use both units), then even the same operations in the same bit of code could produce different results, and cause different templates to be instantiated. There are probably other good reasons too.
But sometimes, you want something baaaaad. Sometimes you want floating point templates, and all the hassles that might come with them. I did. And now you too can experience all the hassles too (actually there are rather fewer hassles, since the implementation of the arithmetic is guaranteed to be the same, whatever the compiler).
And, of course, there's the main reason: for fun!
In my scheme, a floating point number is represented by a class with the following members:
struct this_is_a_floating_point_number
{
static const unsigned int mant = ???;
static const int expo = ???;
static const bool posi = ???;
};
And the resulting number is (2*posi-1) * mant * 2 expo. Note that
IEEE floating point numbers are stored at (1.)xxxxxxxxx (the 1. is implied), where as
in my scheme, this is stored explicitly as an integer. I did also experiment with having
a signed mantissa, but that ended up being more trouble than it was worth. Further, there
is no current representation of additional values, such as inf and nan. These could easily
be added to the floating point representation, but extra logic would have to be added to
every operation.
fp<mantissa,exponent=0,positive=1>
fps<a_signed_integer> generates a floating point type with the same value as the integer
fpd<integer_part,fractional_part> generates a floating point with the decimal value
integer_part.fractional_part
Nums namespace:
neg<num> negates num.
f_abs<num> takes the absolute value of num.
times_2<num> fast multiplication of num by 2.
divide_2<num> fast division of num by 2.
set_sign<num,is_positive> sets the sign of num
is_zero<num>::val is a static boolean with the result.
normalize<num>
add<num1,num2>divide<num1,num2>reciprocate<num>
If we wish to find x such that 1/x - a = 0, then by Newton's method:
xn+1 = 2xn - ax2
Which conveniently does not require any more divisions. The final result seems accurate enough.
reciprocate<C> is derived from reciprocate_error<C,C==0>
reciprocate_error<C,0> does the actual reciprocation
reciprocate_error<C,0> attempts to instantiate something that will break,
but can not be checked until instantiation time.
print<divide<fp<1>, fp<0> > >();the error messages will look like this (highlighted for clarity):
divide.h: In instantiation of 'FPTemplate::divide_error<FPTemplate::fp<1, 0, true>, FPTemplate::fp<0, 0, true>, 0>': fp_template.h:58: instantiated from FPTemplate::divide<FPTemplate::fp<1, 0, true>, FPTemplate::fp<0, 0, true> > fp_template.h:58: instantiated from void FPTemplate::print() [with T = FPTemplate::divide<FPTemplate::fp<1, 0, true>, FPTemplate::fp<0, 0, true> >] ex2.cxx:13: instantiated from here divide.h:76: error: no type named 'divide_by_zero' in 'struct FPTemplate::error_check<FPTemplate::fp<1, 0, true> >'
val with the result in. The tests are:
eq<num1,num2>
gt<num1,num2>
lt<num1,num2>
gt_eq<num1,num2>
less_eq<num1,num2>
exponentiate<num>ex = 1 + x + x2/2! + x3/3! + ...
A Taylor series with a fixed number of terms is only accurate close to the point of expansion. In order to ensure x is small, I use the following result:
ex = (...(((ex/2n)2)2)...)2
conveniently Where n is an integer. Dividing by 2n is easy and accurate. Repeatedly squaring the result makes any errors much worse.
square_root<num>xn+1 = ( xn + a/xn)/2
To get a good starting point, I use the following result:
x = sqrt(b * 2m)
x = sqrt(b) * 2m/2
x = sqrt(2*b) * 2(m-1)/2
Where 1 < b < 2. The approximation:
sqrt(a) = 2m/2
or
sqrt(a) = 2(m-1)/2
is accurate to within a factor of 2 and can be easily be computed. This serves as a good enough starting point that convergence requires only a few iterations.
Error checking for negative roots is performed in a similar manner to division. A typical error looks like:
sqrt.h: In instantiation of 'FPTemplate::sqrt_error<FPTemplate::fps<-1>, 0>': fp_template.h:58: instantiated from FPTemplate::square_root<FPTemplate::fps<-1> > fp_template.h:58: instantiated from void FPTemplate::print() [with T = FPTemplate::square_root<FPTemplate::fps<-1> >] ex2.cxx:16: instantiated from here sqrt.h:53: error: no type named 'attempting_negative_square_root' in 'struct FPTemplate::error_check<FPTemplate::fps<-1> >'
TO_FLOAT and TO_DOUBLE macros. In a positive exponent,
a set first bit corresponds to a multiplication by 221, the second bit by 222, the third by 223, etc...
The macro evaluates to an expression which computes this. Because all the values are determined statically,
compilers (gcc, for instance) will compute the expression at compile time, resulting in a single floating point
literal in the final compiled code. In certain tasks (for instance convolution), having the constants embedded in
the code yields a large speed increase on modern processors, since the constants can come out of the code cache, and
the data can come out of the data cache. This then effectively doubles the bandwidth in to the processor. Speed
increases of nearly a factor of two have been observed.
The function print<num>()
In practice, the system is really too slow to be useful, unless you don't mind half hour compile times. Debugging under those circumstances becomes a little tedious.
imull op-code or abuse the leal op-code in the addressing unit.
It is instructive to compare the assembly output of hand_coded.c to the output of conv_kernel.cxx, side by side. Note that the template generated kernel produces shorter code than the hand coded example.
The two (numerically identical) convolutions were tested for speed on a 2.4 GHz Xeon, with an array length of 1000, 100,000 convolutions per run, results averaged over 100 runs.
| Template based | Hand coded | |
| Mean time (s) | 1.828 | 1.844 |
| Standard deviation | 0.0167 | 0.0243 |
The computed convolution parameters are:
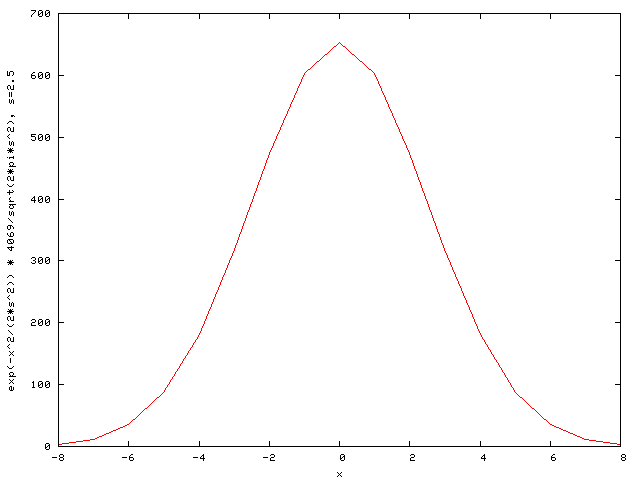
3 12 36 88 181 318 474 603 653 603 474 318 181 88 36 12 3
which can be seen graphically here. The code to generate the convolution kernel takes 7 minutes to compile on a Xeon 2.4.
Not stellar, but I haven't used the best algorithms. This is more of a proof of concept than anything else. The algorithms could be replaced with better ones. Also, several algorithms are missing, such as log and the trigonometric functions. These could easily be implemented using similar techniques
Although the precision of some of operations is not all that good, the range of numbers is very large, since the exponent is a 32 bit signed integer. This allows numbers up to (232-1) * 2231-1.
What use would all this be without the code? Well that can be downloaded here and browsed here. example.cxx contains examples of all the features provided. conv_kernel.cxx is an example which contains some considerably more complex expressions.
Updated July 14th 2011, 10:52
{kind=link}